登陆 & 鉴权
Cookie

Cookie 是浏览器的一种本地储存的方式。
cookie 一般来说是较小的短文本信息,浏览器对同一 domain 下的 cookie 数量有限制,并且每条 cookie 的大小一般也被限制为 4kb。对于储存数据的需求来说,浏览器提供了 IndexDB 或者 localStorage 等等更可靠也更高效的方式,cookie 的意义更多在于共享功能,开发者只需合适地设置属性,浏览器就会自动在一定范围内共享 cookie。
关于 cookie 的各种用途,可以查看 Cookie 。
Cookie 的属性
Cookie 在请求中以键值对的形式展现,形式为<name>=<value>。
但是实际上,cookie 并不只是简单的键值对,只是在请求中如此展现而已。一个很明显的特点是,cookie 是允许重名的,你可以在两个不同网站下发现 name 属性相同的 cookie。
生命周期
浏览器为 cookie 提供了过期设置,浏览器会区分两类来管理 token 的生命周期:
Permanent cookie:
浏览器提供了 ExpiredAt 和 MaxAge 两个属性来控制 token 何时过期。前者是绝对时间的形式,后者是设置时间+offset的形式。如果两者同时被设置,浏览器以 MaxAge 为准。
MaxAge 可以设置非正数,如果这么设置,浏览器会立即删除该 cookie,请求方经常利用这点来删除 cookie。
Session cookie:
如果没有设置前面说的两个生命周期属性,浏览器会将其视作 session cookie,其会在整个 "session" 内保留,直到 "session" 结束后被删除。
不同浏览器对 "session" 的定义不一定相同,比如,如果一个浏览器定义关闭浏览器后 session 才结束,那不关闭浏览器的话,session cookie 就永远不会过期(当然这样不太安全,大多浏览器都是设置了一个最大时间)。
访问限制
Cookie 只是存在客户端本地的一段文本信息,本身十分不安全。为了提高 cookie 的安全性,浏览器限制了其访问途径。
一般来说,cookie 是通过 http 请求设置和传递的,在一个请求头中携带 Header Set-Cookie就能让浏览器自动设置好 cookie,已经设置过的 cookie 会被携带在Cookie 中发送/返回:
HTTP/2.0 200 OK
Content-Type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
GET /sample_page.html HTTP/2.0
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry
这个过程中 cookie 的管理全部由浏览器完成,但是,前端也可以主动访问并设置 cookie,比如,js 可以通过 document 访问这个页面的 cookie:
document.cookie="username=John Doe; expires=Thu, 18 Dec 2043 12:00:00 GMT";
浏览器提供了 HttpOnly 属性来限制前端以这种方式访问 cookie,这样 cookie 就只能在 http 请求中携带。
虽然但是,浏览器只是限制了部分 js 访问接口,还是有很多方式能获取到 cookie 的(比如有些 php 网页就能访问到 HttpOnly 的 cookie),这个属性不代表绝对安全。
Secure 属性可以限制只有使用 https 协议的请求可以携带/设置 cookie,这样可以尽可能防止 cookie 在传输过程中被泄露。
作用范围
几乎所有网页都使用了 cookie,浏览器需要区分不同网站设置的 cookie。
Domain 和 Path 属性可以限制 cookie 所属的网站。浏览器只会将某条 cookie 携带在发给符合限制的网站的请求中。
Domain 限制了 cookie 所属的域名。浏览器默认会匹配所有的子域名,例如设置了domain=feishu.cn,则所有其下的子域名,如docs.feishu.cn都算在内。
如果不设置 domain 属性,浏览器则会将该请求的 target 作为 domain 属性,并且不会匹配子域名,也就是说,不主动设置 domain,浏览器对 cookie 的限制反而更严格。
Path 属性限制了 cookie 所属的子路径。如果不设置 path 则默认为/。path 无论是否主动设置,都匹配所有的子路径,比如,/ 可以匹配如 /docs和/。
我们知道可以有 name 重复的 cookie。浏览器以 domain+path 来设置 cookie 的作用范围,在一个范围内(即 domain 和 path 字面量相同)的 name 是唯一的,但是不同的范围内可以有重名 cookie。
CSRF 和 SameSite
看似我们的 cookie 已经比较安全了。但实际上它存在一个致命缺陷。
当我们已经在一个网站 A.com 获取了用户的登录 cookie,此时如果网站 B.com 向 A 发送了一条请求,其符合我们之前的所有限制条件(范围限制),所以会带着该 cookie 进行请求。如果 B 利用这一点向 A 发送恶意请求,就能利用到 A 自己设置的鉴权 cookie,产生严重后果。这是 CSRF 的一种形式。
这里需要另外介绍以下 跨域 和 跨站 的区别。
站 Site 的概念一般由域名来区分。一般来说,域名服务商只售卖 xxx.xx 这样两层的 “二级域名”,再扩展的多级域名都属于二级域名的所有者。因此,我们将二级域名相同的网址称为 Same Site。
根据 MDN ,有时 site 的限定除了二级域名,还要求了协议。但是在我们之后的讨论范围内,site 都只限制二级域名,不限制协议。
而域 Origin 的限制要严格的多,只有两个网址的 schema, host, port 全部相同,才能被称作同域。
一些栗子:
- http://example.com & http://qwq.example.com 同站,不同域
- http://qwq.example.com & https://qwq.example.com 同站,不同域
- http://qwq.example.com:80/api/ & http://qwq.example.com 同站,同域 (http默认在80)
如果我们假设 “同站” 的网站一般属于同一所有者,那么基本上同站之内不会发生上述攻击,并且可能期望共享 cookie。因此,浏览器对 cookie 做了一个 site 级别的限制。
SameSite 属性指定了限制的级别,有三个级别: strict|lax|none。
最严格的strict模式,任何跨站的 cookie 都不会被携带,意思是说,如果从 A.com 向 B.com 发送请求,不会携带任何 B.com 所属的 cookie。这样当然很安全,但是很不方便。例如,如果我们在文档里嵌入一个分享链接,那么用户点击这个链接跳转到相应网站时,不会携带任何 cookie。如果分享的是一个 github 链接,跳转过后用户会发现自己是未登录状态,必须重新刷新才能发送 cookie 然后刷新出登录信息。
因此,lax模式就是将一部分请求方式从限制中移除,其中就有<a>标签,这样跳转链接这种请求就不会因为跨站而被限制 cookie。具体开放的请求方式,可以参考 这里。
none级别就是完全不进行 SameSite 限制。不过为了有最基本的安全保障,只有设置了 secure(只能通过 https 传输) 的 cookie 可以被设置为SameSite=none。(至于具体浏览器怎么处理没设置 secure 的请求就不一定了,比如 safari 会将这种 cookie 直接设置为strict)
SameSite 似乎正在从none改为lax,很可能不同浏览器的表现不一样。
CORS
浏览器内有很多内置资源,比如页面 dom, localStorage, cookie 等等等等。如果让任何网站都能访问这些资源是很危险的。
我们之前已经说明过跨站 cookie 共享可能产生的 CSRF 问题。相似的还有 XFS,这是一种因为共享 dom 产生的问题,攻击者可以用 inline frame (常见用途是页面内嵌其他网页,比如嵌一个地图) 伪造成一个其他的网页,并且访问目标网站的 dom,之后攻击者就可以监听到目标网站的几乎所有动作。如果目标网站是一个银行网站,就有可能被监听到密码之类的信息。
CORS 即是为了应对这种问题。CORS 可以限定一个请求的来源和可以访问的资源。上面说的 CSRF、XFS 等等问题,可以通过 CORS,从服务器端限制请求来源,直接拒绝来源不明的请求,从而免去大多数攻击风险。
严谨来说,是浏览器限制了跨域请求,**CORS** 不是 “限制” 的规则,反而是在限制下进行 “共享” 的规则。
但是懒得改了,大家意会就好x
实现流程
顾名思义,CORS 在 origin 级别进行限制请求,其本质上是基于请求 HEADER 的一种约定限制。
CORS 将请求分为两类,一种是 simple request,其他都是 non-simple request。
其初衷是按照 是否有副作用 (side-effect) 来分类请求。对于有副作用的请求,我们不能将其直接发送给服务器,必须先验证这个请求是否合法,因此是 non-simple request。对于没有副作用的请求,我们将其发送给服务器也没有什么影响,所以不妨直接发送请求,返回时再验证,并将不合法的请求直接丢掉,于是叫 simple request。
我们以一个 non-simple request 来举例。在实际发送请求前,需要先发送一个 OPTION 请求作为 preflight:
OPTIONS /doc HTTP/1.1
...
Origin: http://example.com
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
如上,在 OPTION 请求中会携带三个额外的 HEADER。Origin 声明了请求的发送者的域,后两者则分别指定了该请求的 Method 和 Headers。
由服务器接收到请求后,服务器在返回中设置以下字段,来告诉发送方自己接受的请求类型:
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Credentials: true
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400 // 对options的缓存
Access-Control-Allow-Origin是对域的限制,可以指定多个域,比如设置为http://localhost:63342/``, http://localhost:1926,表示接受两个域,也可以像上面那样设置为通配符*,表示接受所有域。
后两者同理是向请求方表明自己接受的 Method 和 Headers。
Access-Control-Allow-Credentials表示服务器是否接受 cookie,如果设置为 false,之后的请求中服务器就不会携带 cookie(注意,OPTION 请求是不会带 cookie 的)。
Access-Control-Max-Age请求表示请求方对这个 OPTION 请求的缓存时间,如果在缓存时间内,下次发送相同的 CORS 请求时,请求方可能就不会再发送一个 OPTION 请求,而是使用上一次 OPTION 请求的数据。
发送方接收到响应后,验证服务端是否能够接受实际要发送的 CORS 请求,如果不满足服务端的要求,就不再发送实际的请求。如果 preflight 请求通过了,则继续发送正式的请求,这回只用携带 Origin 就行了
POST /cors HTTP/1.1
Origin: http://example.com
Host: example.com
Accept-Language: en-US
Connection: keep-alive
User-Agent: Mozilla/5.0...
服务器接收到正式请求后,按照正常方式响应,但是多加了几个 Hedaer:
Access-Control-Allow-Origin: http://example.com
Access-Control-Allow-Credentials: true
Access-Control-Expose-Headers: X-Header
有一部分是之前 preflight 请求里出现过的,请求方会再次检查,如果有不符的地方仍然会丢弃请求。
Access-Control-Expose-Headers的作用是告诉请求方能够接受的响应头,CORS 请求的请求方默认只能拿到响应头的一部分(详见reference),如果需要另外使用自定义的 Header,需要服务端在这个 Header 里指明,请求方才能拿到。
而对于 simple request,因为没有副作用,完全可以直接发请求,再由请求方校验,决定要不要丢弃请求即可。因此只需要进行上述流程的后两部分。
关于通配符
上面几乎所有的Access-Control-Allow-XXX字段,服务端都可以使用*来代表接收所有选项。
特别的,设置了Access-Control-Allow-Origin: *时,Access-Control-Allow-Credentials就不能设置为true,请求方会默认将此值当 false 处理。
一个实际开发中非常值得注意的点是,当因为 CORS 的配置问题导致 cookie 被吞时,请求方 (至少对 FetchAPI 来说) 不会收到任何报错,因为这是预期内行为,这可能对开发产生困扰。
另外,对于大多数限制了跨域请求的 api 来说,cookie 不仅要被服务端允许发送,还需要自己手动设置发送策略,比如,fetch API 需要使用参数credentials: include,XMLHttpRequest 需要设置withCredentials。
具体使用
在上面的流程中,不难意识到,所有的 CORS 限制都是由请求方来做的。服务器方只不过配置了对 OPTION 请求的响应和一些固定的 Header 字段,所有的验证都和服务端无关。如果请求方不按校验规则来,服务器是一点办法都没有。
实际上,浏览器的 CORS 限制是由其提供的 API 实现的。一般来说,我们在浏览器中使用FetchAPI或者XMLHttpRequest来发送请求,这些 API 都遵循 CORS 规则限制。
反过来说,我们其实可以通过不使用这些 API 来绕过 CORS。一个最典型的例子是微信小程序的开发,开发者往往不需要关心 CORS 设置,因为微信小程序提供的 request API 是没有实现 CORS 的,不会限制跨域请求。普通浏览器中也有许多没有 CORS 限制的请求方式,比如利用<script>块的src属性进行请求(据说真有利用这个特性做的 no-cors request 库,我只能说好家伙)。
另一方面,既然服务器要做的只是配置相应的 Header 字段供请求方验证,这些工作完全可以在路由部分完成。所以一般服务端的 CORS 实现就是在所有路由最外层挂一个中间件,用以设置 Header,顺便给 OPTION 请求响应 204。或者也可以用 nginx 在代理层就实现这一点。
登录 & 鉴权
密码学科普
既然要讲登录,就不得不先提一些关于加密的常识。
- Hash,常用算法有 SHA2,利用难以求得反函数的 Hash 函数来加密数据,不可逆
- 对称加密,常用算法有 AES,使用一个保密的密钥,可以使用密钥对信息进行加解密
- 非对称加密,常用算法有 RSA ed25519 等,有两个成对的密钥,分别为公钥和私钥,用其中一个密钥加密的信息,只有用另一个密钥才能解密。所以可以保存私钥,发布公钥,这样别人就能通过公钥加密信息然后发给私钥持有者,不用担心中途密钥泄露造成风险。
- 加盐。当 Hash 的结果空间太小时,其实可以用暴力枚举的方式,生成一张 hash 函数的反函数表(被称作 rainbow table)来破解加密。所以,我们 Hash 时,一般都要在原信息中拼接一段随机信息来保证长度。这一串拼接的 byte 串就被称作 "salt",这个过程也就叫做 “加盐”。
- 签名,一种防止公开发布的消息是否被篡改的方式。常用的方法有 MAC,可以理解为一种带密码的 Hash,只有有正确密钥的人才能 Hash 出相同的值。上述的非对称加密也可以用作签名,只需反过来使用,用私钥加密,公钥解密,这样就能确认只有私钥拥有者才能发布信息。
- 对称+非对称混合加密。对称加密在交流时,必须要先传递密钥,但是传递密钥本身就可能不安全。非对称加密免除了密钥泄露的风险,但是根据加密信息长度增加,加密效率将指数级上升。所以我们经常使用非对称加密加密对称加密的密钥,然后用对称加密加密主要信息。这样既安全又高效。
- TLS。https 通过 TLS 协议保证安全性。其也是由上述的对称+非对称加密来传递信息,只不过加上了数字证书验证服务器身份的过程。
Strawman Example
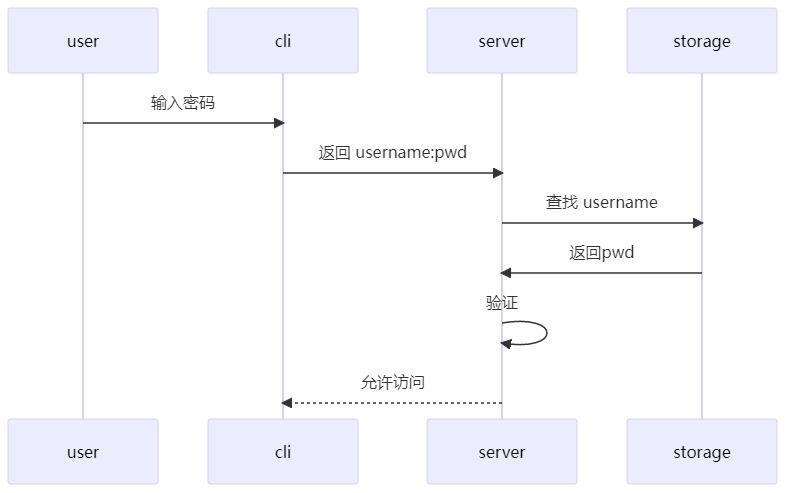
如上是一个非常离谱的登录实现,我们可以以此为例想象一下登录过程可能会出现什么问题。
首先是安全问题,这样直接传递密码可能会被人中途抓包,于是会造成信息泄露,暴露用户密码。
一种最朴素的解决方法是用非对称加密来传递密码,这样就算被截获了请求,对方还是不知道密码是什么。但是问题并没有被完全解决,截获者可以不用破解密码,直接将原请求发给服务器,这种攻击方式被称为 “中间人攻击”,其根本原因是我们并没有办法验证消息发送者的身份。
使用 HTTPS 协议时,因为可以确认发送者的身份,我们就能够防止中间人攻击了。实际上,如果使用了 HTTPS,我们基本上就不用担心什么传输过程中的安全问题了。
于是乎,我们从安全问题上移开视线,关注另一个问题,请求次数。上述流程中,每次需要验证权限的操作,都需要向服务端传递密码。如果每次让用户手动输入,那体验想必是极差的,但是要把用户密码在客户端缓存,又会产生额外的安全问题。另外,虽然我们保证了传输过程是比较安全的,但是要是每次请求都带有密码,请求次数一但增多,谁能保证攻击者不从中分析出有用的信息呢(参考某Enigma)。
解决此问题的方法是将权限验证分为两个过程,Login & Authentication。登录被单独拿出来作为一个单独的操作,用户需要传递密码或以其他方式证明身份来登录,登录后,其他的请求则不需要用户再传递密码。为此,我们需要一些机制,能够验明其他请求的身份,如使用session、token等等。
这个 strawman example 还有一些服务端的安全漏洞。攻击者虽然无法破解 HTTPS 的安全性,但是服务端自己的数据库却不一定是绝对安全的,攻击者有可能通过注入等途径来获取到数据库内容。那么我们在数据库里直接储存用户密码就是很不安全的一件事情。
一般来说,我们存数据库时实际存的是加盐 hash 后的用户密码,每次验证时,将用户密码再按原来的方法 hash 一遍,对比验证。这样即使漏库了,也不太会泄露用户密码。
这样做还有一个好处,就是我们的数据库本身也不知道用户的实际密码。很多人有在不同应用使用同一个密码的习惯,所以他们可能不希望服务端知道他们的密码。有些密码管理器应用,甚至会在客户端传回密码前都要先进行一次加密,保证服务端从头到尾都不知道原密码是什么。
一些常见的鉴权实现
Token
Token 是最常见的一种鉴权方式,有很多鉴权规范其实都是在使用 token。
此处以 postman 中提供的预设方式为例,其实 API Key, Bearer Token, Basic Auth 都是一种 token,后面的 session 其实也是一种 token,只是具体如何生成,如何在请求中传递等等细节不同而已。
使用 token 鉴权的流程一般是这样的:用户在登录后,服务端生成一个代表其身份的令牌,这就是 token。然后服务端将这个 token 返回给客户端,之后的请求,客户端只需要携带这个 token 进行请求即可。服务端通过 token 验证用户的身份。
Token 的安全问题主要出在客户端(不会有人不用 https 吧),和之前讨论密码时一样,储存的客户端的数据不一定能保证安全。所以 token 主要是靠过期来提高安全性的,根据具体的安全性和用户体验之间的权衡,可以调整过期时间的长短。
Session
Session 是最简单的一种 token 实现。在用户登录后,服务端生成一个 sessionID 并储存起来(一般我们使用类似 uuid 的方式来生成 sessionID),然后将此 ID 返回给客户端。之后客户端就可以带着 sessionID 请求,服务端每次去 数据库/缓存 里查询这个 ID 对应的用户,就能实现鉴权了。
因为储存了每个用户登录的 session,服务端可以具体管理每个登录会话的状态。比如,当用户 A 更改了密码,服务端可以手动将所有 A 的 session 删除来实现强制注销。甚至还可以在 session 之上做登陆记录留痕等等。
JWT
JSON Web Token 是 token 的一种特殊实现。
Jwt 主要的特点在其 token 的生成方式上。jwt 可以在 token 中携带一些用户信息(但是不能是敏感信息,jwt 没对信息做加密),在生成时,jwt 会使用一个密钥,对整条 token 用 HMAC 做一次签名,从而防止有人篡改。
具体的 jwt 生成方式:
JWT 可以将用户信息携带在 token 中,因此每次鉴权时不需要像一般的 token 一样再去查找对应的用户信息,因此鉴权的压力会小一些。而且对于某些分布式的服务,使用 session 鉴权需要另外考虑 session 数据的同步问题,而 jwt 就不需要考虑这一点。
在实践中,我们常常将权限分成不同的 scope,然后直接将用户拥有的 scope 写在 jwt 里。如此依赖,我们只需要解析 jwt 就能知道用户是否有某个 api 的权限,完全不用做查找用户数据库等操作。
因此我们常说 jwt 是 无状态 (context-less) 的。
(无状态的缺点是我们无法做到像 session 那样的强制注销操作)
Oauth
Oauth2 规范是一种用于第三方授权的鉴权方式。
你可以想象为, Oauth 将鉴权逻辑完全分离,有一个专门的 “权限管理中心” 来管理权限。其将客户端和用户的角色完全分开来,由用户通过这个 “权限管理中心” 给客户端赋予权限(基本也是用 token 的方式授权的),然后客户端再去请求拥有相关资源的 API。
Oauth 的核心内容是 “如何让用户经由一个权限管理中心来赋予客户端权限”。其标准定义了四种方式,以适应不同的运用场景。我们这里就以 web 应用最常见的工作方式来说明。
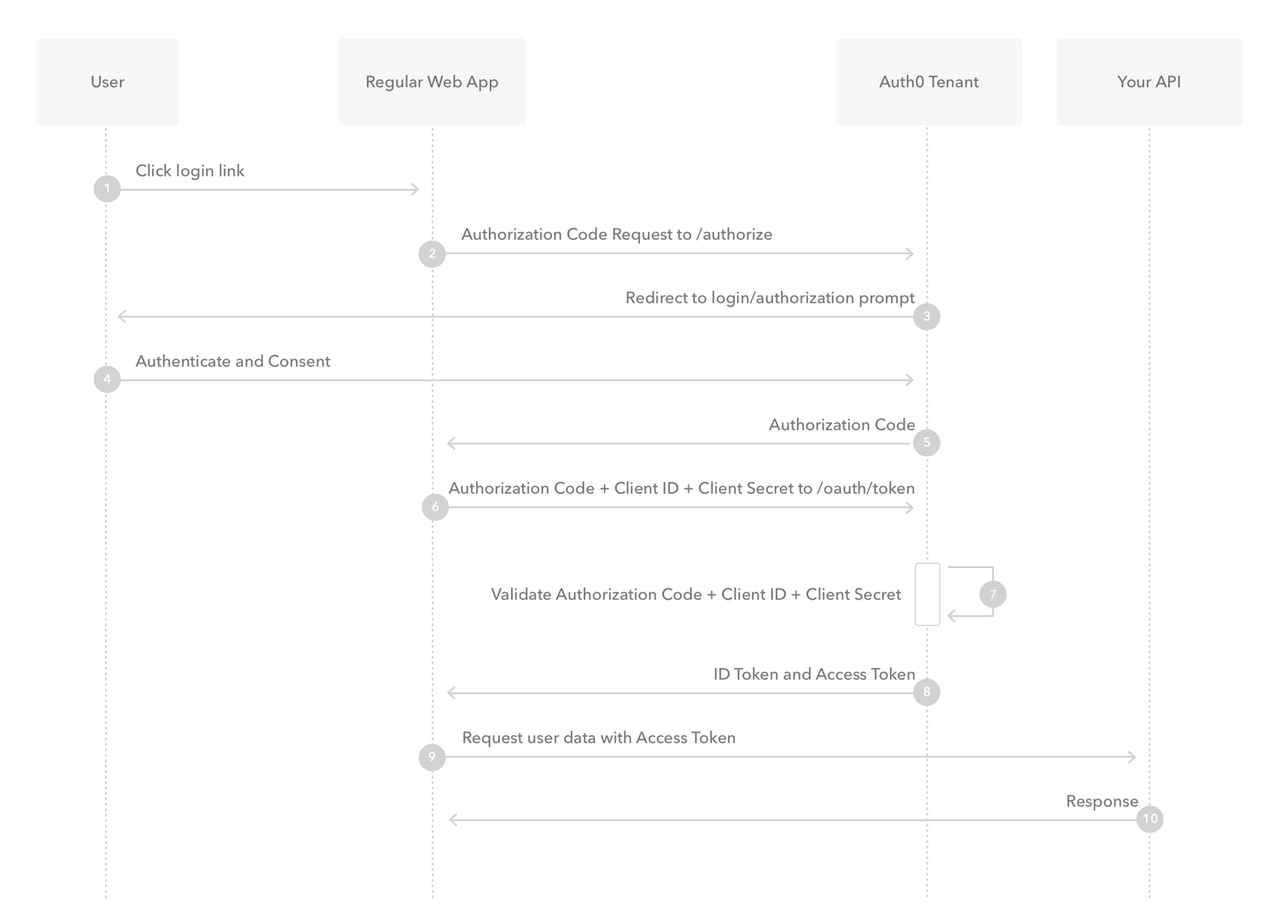
如上图,在这张图中有四个角色。其中,Regular Web App 就是我们的应用,而 Auth Tenant 是所谓的权限管理中心,API 则是其负责管理的资源 API。而我们的应用需要请求这些 API 获取用户能够取得的资源。
用户登录时,应用会向权限管理中心发送一个授权请求。而后,授权中心将这个请求 redirect 到其提供的授权页面用户在这个页面上登录即可(参考浙大统一认证登录,或者第三方应用的 google 登录)。
用户登录成功后,这个权限管理中心会携带着必要的授权信息,redirect 到一个我们的应用预先定好的地址上。这样授权就基本完成了。
后面的操作因具体场景而异,有的应用需要进一步去权限管理中心获取进一步的 access token,以请求资源 API (比如某些第三方应用需要获取用户的 google calendar 权限),有的应用只是利用第三方认证登录而已,只需要拿到用户 ID 等必要的用户授权信息就行了(比如某些第三方应用完全不需要获取用户 google 账号的资源,只是允许你用 google 账号登录而已),这些实现的细枝末节就不仔细讨论了。
一些栗子
Refs:
扩展阅读
Linux上的高级用户鉴权技术
https://zhuanlan.zhihu.com/p/266491528
思考题
用自己的话介绍一些典型权限攻击模式
- 重放攻击
- 劫持攻击
- 旁路攻击
通过什么样的API设计,可以应对这些攻击?